
# JavaScript 正则表达式从入门到实践,正则相关工具
TIP
如果我们想对字符串进行相关(增、删、改、查、检索)操作,就可以用接下来的正则表达式实现
什么是正则表达式
- 正则表达式是用于匹配字符串中字符组合的模式
- 正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本
在实际开发中,我们需要检测用户输入的账号(邮箱或手机号)是否符合要求,就可以用到正则表达式来检测
我们通过下面这个简单的案例来了解下正则表达式:检查某个字符串中是否包含连续的 5 位数字
// 需要检查的字符串
var str1 = "123a456";
var str2 = "1234567";
// 创建正则表达式
var reg = /\d\d\d\d\d/; // \d 表示 0-9之间的任意一个数字
// 检查
console.log(reg.test(str1)); // false
console.log(reg.test(str2)); // true
# 一、创建正则表达式
TIP
创建正则表达式有两种方式:字面量形式和构造函数形式
- 字面量形式 : 由两个斜杠
/ /包围 ,如/正则内容/ - 构造函数形式 :使用
new RegExp('正则内容')的形式创建
正则表达式是对象(引用数据类型),使用 typeof 运算符检查正则表达式的类型,结果为
Object
// 需要检查的字符串
var str1 = "123a456";
var str2 = "12345a67";
// 字面量形式创建正则表达式
var reg1 = /\d{5}/; // 配的字符串中需要包含连续的5位数字
// 构造函数形式
var reg2 = new RegExp("\\d{5}");
console.log(reg1.test(str1)); // false
console.log(reg1.test(str2)); // true
console.log(reg2.test(str1)); // false
console.log(reg2.test(str2)); // true
typeof /\d{5}/; // 'object'
- 能用字面量方式实现,就用字面量方式。如果字面量方式实现起来不方便,则可以考虑用
new RegExp实现
// 以下正则表达式的规则是可变的,不固定的,可以把正则表达式以字符串形式保存在变量中,然后在new RegExp中引用这个变量。
var str = "uabc";
var val = "a"; // val可以更改为u,b,c都可以
var reg = new RegExp(val);
console.log(reg.test(str));
正则表达式”按位“描述规则
- 正则表达式 "按位" 描述规则,是指它是一位一位的描述字符串的构成形式
- 比如:检测某个字符串是不是:以 A 开头,中间 3 个数字,最后以 B 结尾
// ^表示开头,$表示结尾,\d表示数字
// \d\d\d 也可以写作 \d{3}
var reg = /^A\d\d\dB$/;
reg.test("A123B");
正则在线测试工具:https://regexr-cn.com (opens new window) 可以用来测试自己写的正则
# 二、边界限定字符
| 字符 | 描述 |
|---|---|
^ | 匹配输入字符串的开始位置 |
$ | 匹配输入字符串的结束位置 |
\b | 匹配一个单词的边界,需要注意的是匹配的单词边界不包括在匹配中 |
\B | 匹配非单词边界 |
- 检测字符串是否是 5 位数字
var str1 = "a12345";
var str2 = "12345b";
var str3 = "12345";
var reg = /^\d{5}$/;
console.log(reg.test(str1)); // false
console.log(reg.test(str2)); // false
console.log(reg.test(str3)); // true
console.log(reg.test(str4)); // false
- 检测字符串是否是以 m 开头,中间 5 位数字,以 n 结尾
var str1 = "m12345";
var str2 = "m123456n";
var str3 = "m12345n";
var reg = /^m\d{5}n$/;
console.log(reg.test(str1)); // false
console.log(reg.test(str2)); // false
console.log(reg.test(str3)); // true
- 将字符串中独立的 cat 前后加上
*号
var str = "cat scats";
var reg = /\bcat\b/g;
var res = str.replace(reg, function (v) {
return "*" + v + "*";
});
console.log(res); // *cat* scats
- 找出以 icon 开头的单词,不包括 icon
var reg = /\bicon[a-z]+\b/gi;
var str = "i icons bicon iconasw icons1 icon";
console.log(str.match(reg)); // ['icons', 'iconasw']
- 找出单词中出现的
icon换成*,但要求icon不能出一在单词的开始和结束
var reg = /\Bcon\B/gi;
var str = "content iconfont bacon";
var res = str.replace(reg, function (v) {
return "*";
});
console.log(res);
- 单词前后出现(
@ . - # $ % & <)等特殊字符,这个单词都可以看作是独立的单词 - 如果单词前后出现 数字、字母、
_则不会当前独立的单词
// 匹配字符串中的独立的cat单词
var reg1 = /\bcat\b/g;
var str = "cat 1cat cats cat. @cat -cat _cat";
var res = str.replace(reg1, function (v) {
return "*" + v;
});
console.log(res); // *cat 1cat cats *cat. @*cat -*cat _cat
# 三、元字符
TIP
- 根据正则表达式语法规则,大部分字符仅能够描述自身,这些字符被称为普通字符,如所有的字母、数字等
- 元字符就是拥有特定功能的特殊字符,大部分需要加反斜杠进行标识,以便于普通字符进行区别
- 元字符是正则表达式中的最小元素,只代表单一(一个)字符
| 元字符 | 功能 |
|---|---|
\d | 匹配一个数字,等价于 [0-9] |
\D | 匹配一个非数字字符 [^0-9] |
\w | 匹配一个单字字符(字母、数字、下划线) 等价于[A-Za-z0-9_] |
\W | 匹配一个非单字字符 [^A-Za-z0-9_] |
\s | 匹配一个空白字符,包括(空格、制表符和换行符) |
\S | 匹配任意不是空白符的字符 |
. | 匹配除换行符之外的任何单个字符 |
- 检测字符串是否满足:
123-4567-789格式
// 正则表达式
var reg = /^\d\d\d-\d\d\d\d-\d\d\d$/;
// var reg = /^\d{3}-\d{4}-\d{3}$/; 优化版
// 测试字符串
var str1 = "123-9873-980";
var str2 = "123-9873-9803";
console.log(reg.test(str1)); // true
console.log(reg.test(str2)); // false
- 检测字符串是否满足
xxx-xxxx-xxx格式,其中 x 表示字母、数字、下划线
// 正则表达式
var reg = /^\w\w\w-\w\w\w\w-\w\w\w$/;
// var reg = /^\w{3}-\w{4}-\w{3}$/;
// 测试字符串
var str1 = "123-a123-bc9";
var str2 = "abc-_e13-cde";
var str3 = "@bc-_ae13-cde";
console.log(reg.test(str1)); // true
console.log(reg.test(str2)); // true
console.log(reg.test(str3)); // false
- 检测字符串中是否有空白字符
// 正则表达式
var reg = /\s/;
// 测试字符串
var str1 = "1 bc";
var str2 = " ab";
var str3 = "se1";
console.log(reg.test(str1)); // true
console.log(reg.test(str2)); // true
console.log(reg.test(str3)); // false
- 检测字符串的开头是否有空白字符
// 正则表达式
var reg = /^\s/;
// 测试字符串
var str1 = "1 bc";
var str2 = " ab";
var str3 = "se1";
console.log(reg.test(str1)); // false
console.log(reg.test(str2)); // true
console.log(reg.test(str3)); // false
# 1、注意事项 1:字符转义
TIP
- 如果想让某个特殊字符以字面意思理解(匹配),则可以在特殊字符前加
\转义 - 在特殊字符之前的反斜杠
\表示下一个字符不是特殊字符,应该按照字面理解 .点在正则中是一个特殊字符,表示匹配除换行符之外的任何单个字符- 如果我们想检测字符串是否有
.,则需要在其前加\来转义
// 正则表达式
var reg1 = /^a\.b$/; // 字符串要有.字符
// 测试字符串
var str1 = "abc";
var str2 = "a.b";
console.log(reg1.test(str1)); // false
console.log(reg1.test(str2)); // true
温馨提示
不管一个符号有没有特殊意义,都可以在其之前加上一个\以确保它表达的是这个符号本身
// 匹配字符串
var str1 = "@.^/";
// 正则表达式
var reg1 = /^\@\.\^\/$/;
console.log(reg1.test(str1)); // true
# 2、注意事项 2:字符串中的 \
TIP
字符串中的\是一个转义符,如果想在字符串中正确的输出\,需要在他的前面再添加\转义
var str1 = "a\\b";
console.log(str1); // a\b
# 3、注意事项 3:new RegExp() 中的 \
TIP
- 如果使用
new RegExp()写法创建正则表达式,反斜杠需要多写一个,原因就是因为字符串中的\本身是一个转义符 - 如:
/^\d$/和new RegExp('^\\d$')是相同的意思
// 正则表达式
var reg1 = /^\d{5}$/; // 字符串是5位数字组成
var reg2 = new RegExp("^d{5}$"); // 检测的字符串要是5个d
var reg3 = new RegExp("^\\d{5}$"); // 字符串是5位数字组成
// 测试字符
var str1 = "12345";
console.log(reg1.test(str1));
console.log(reg2.test(str1));
console.log(reg3.test(str1));
console.log(reg2.test("ddddd")); //true
# 四、方括号表示法
TIP
在正则表达式语法中,[]放括号表示字符范围,在方括号中可以包含多个字符,表示匹配方括号中出现的任意一个字符
# 1、[] 中特殊字符
TIP
在 [] 方括号中,对于. * ?|/ 等这些特殊符号,没有任何特殊意义,只是表示字符本身的意思
var reg = /^a[123]b$/;
console.log(reg.test("a1b")); // true
console.log(reg.test("a3b")); // true
console.log(reg.test("a4b")); // false
var reg = /^[1a/.*?]$/;
console.log(reg.test(".")); // true
console.log(reg.test("/")); // true
console.log(reg.test("*")); // true
console.log(reg.test("?")); // true
console.log(reg.test("|")); // true
# 2、[ ] 中的破折号 -
TIP
如果多个字符的编码顺序是连续的,可以仅指定开头和结尾字符,省略中间字符,使用破折号 -来指定字符范围
| 字符范围 | 描述 |
|---|---|
[0-9] | 匹配0-9之间的一个数字 等价于 \d |
[a-z] | 匹配小写 a-z 任何一个字母 |
[A-Z] | 匹配大写 A-Z 任何一个字母 |
[A-Za-z0-9_] | 匹配一个单字字符(字母、数字、下划线) 等价于 \w |
[a-d] | 表示匹配 a,b,c,d 中的任意一个 |
[0-4] | 表示匹配 0,1,2,3,4中的任意一个 |
- 字符串是否是
0-5之间的任意一个数字
var reg = /^[0-5]$/;
console.log(reg.test("1")); // true
console.log(reg.test("2")); // true
console.log(reg.test("6")); // false
- 验证字符串是否为 Java 或 java
var reg = /^[Jj]ava$/;
console.log(reg.test("java")); // true
console.log(reg.test("Java")); // true
console.log(reg.test("zJava")); // false
- 匹配某字符串是否符合以下要求:字符串由 11 位数字组成,第 1 位不能是 0,第二位只能是
3,5,6,7,8中任意一位,最后 9 位为任意数字
var reg = /[1-9][35678]\d{9}/;
console.log(reg.test("13123456789")); // true
console.log(reg.test("14123456789")); // false
console.log(reg.test("05123456789")); // false
- 验证某个字符串是否为 5 位,且仅有字母、
.点、-横线、_下划线、@符组成
var reg = /^[a-zA-Z\.@_-]{5}$/;
// var reg = /^[a-zA-Z.@_-]{5}$/; 点在方括中没有特殊含义
console.log(reg.test("ab@cd")); // true
console.log(reg.test(".b@cd")); // true
console.log(reg.test(".@cd3")); // false
console.log(reg.test("-_Wde")); //true
- 验证某字符串是否是 4 位小写字母,且最后一位不能是
m
var reg = /^[a-z]{3}[a-ln-z]$/;
console.log(reg.test("abcf")); // true
console.log(reg.test("1abc")); // false
console.log(reg.test("abcm")); //true
console.log(reg.test("abmc")); //true
# 3、取反:[ ] 内添加^前缀
TIP
如果在方括号内添加^前缀,表示只要不是当前范围内的任意一个字符
| 字符范围 | 描述 |
|---|---|
[^0-9] | 匹配一个非数字字符 等价于\D |
[^a-z] | 匹配一个非小写 a-z 中的任何一个字符 |
[^A-Z] | 匹配一个非大写 A-Z 任何一个字符 |
[^A-Za-z0-9_] | 匹配一个非单字字符 等价于 \W |
[^123] | 匹配非 123 中的其它任何一个字符 |
检测某个字符串是否符合以下要求: 字符串有 3 位字符组成,以小写字母开头,中间 1 位不能是数字,最后一位不能是大写字母
var reg = /^[a-z][^\d][^A-Z]/;
console.log(reg.test("asA"));
console.log(reg.test("a.s"));
# 4、匹配所有字符
TIP
[\d\D]可用来表示所有字符[\s\S]可用来表示所有字符
var str = "12ab./@*&^%#";
var bool = /^[\s\S]+$/.test(str);
console.log(bool);
var res = str.match(/[\s\S]+/g);
console.log(res); // ['12ab./@*&^%#']
# 五、量词
TIP
如果需要重复匹配一些内容时,我们就需要使用到量词,主要包括以下几种
| 量词 | 描述 |
|---|---|
* | 匹配前一个表达式 0 次或多次,等价于{0,} |
+ | 匹配前面一个表达式 1 次或多次,等价于{1,} |
? | 匹配前面一个表达式 0 次 1 次,等价于{0,1} |
{n} | n 是一个正整数,匹配了前面一个字符刚好出现了 n 次 |
{n,} | n 是一个正整数,匹配前一个字符至少出现了 n 次 |
{n,m} | n 和 m 都是整数,匹配前面的字符至少次,最多 m 次 |
- 验证字符串是否符合手机号码的规则:11 位数字,并且肯定要以 1 开头,第 2 位不能是 1 和 2
var reg = /^1[3-9]\d{9}$/;
console.log(reg.test(13978903158)); // true
console.log(reg.test(138534080452)); // false
console.log(reg.test(12853342345)); // false
- 判断某个字符串是否是 5 位,要求以大写字母开头,中间任意数字,最后以小写字母结尾
var reg = /^[A-Z]\d{3}[a-z]$/;
console.log(reg.test("A012Q")); // false
console.log(reg.test("A012m")); // true
console.log(reg.test("A0123s")); // false
- 验证用户名是否符合以下规则:
4-16位,只能是数字,字母,_下划线,-减号组成
var reg = /^[\w-]{4,16}$/;
console.log(reg.test("a123s@")); // false
console.log(reg.test("a123s-as")); // true
- 判断某个字符串是否是以 http 或 https 开头
var reg = /^https?/;
console.log(reg.test("http")); // true
console.log(reg.test("https")); // true
console.log(reg.test("httsp")); // false
- 判断某个字符是否是小数,比如
3.143.01
var reg = /^\d+\.\d{2}$/;
console.log(reg.test("1.209")); // false
console.log(reg.test("0.12")); // true
console.log(reg.test("21.s2")); // false
console.log(reg.test("1.209")); // false
# 六、选择符
| 选择符 | 说明 |
|---|---|
| | 这个符号代表选择修释符,由|分隔的部分称为一个可选项,| 左右两侧有一个匹配到就可以x | y 匹配x或者y |
|选择符:一般会放在原子组()中来使用
- 匹配字符串中只要包含 a 或 b 就可以
var reg = /a|b/; //相当于,只要匹配 /a/ 或 /b/ 就可以
console.log(reg.test("12a2wq")); // true
console.log(reg.test("12bwq")); // true
console.log(reg.test("12wq")); // false
- 匹配字符串是否以 a 开始或 b 结尾
var reg = /^a|b$/; // 相当于,只要匹配 /^a/ /b$/
console.log(reg.test("a")); // true
console.log(reg.test("b")); // true
console.log(reg.test("ab")); // true
console.log(reg.test("1swb")); // true
console.log(reg.test("ws122")); // false
- 匹配字符串是否是 a 或 b
var reg = /^(a|b)$/; // 相当于只要匹配 /^a$/ 或/^b$/ 就可以
console.log(reg.test("a")); // true
console.log(reg.test("b")); // true
console.log(reg.test("a11")); // false
console.log(reg.test("ssb")); // false
- 匹配字符串是否为 “current”或 “active”
var reg = /^(current|active)$/;
console.log(reg.test("current")); // true
console.log(reg.test("active")); // true
console.log(reg.test("actives")); // false
- 匹配字符串是否为 hobby 或 hobbies
var reg = /^hobb(y|ies)$/;
console.log(reg.test("hobby"));
console.log(reg.test("hobbies"));
console.log(reg.test("hobbes"));
- 检测坐机电话是否是长沙或西安的 长沙区号:0731 、西安区号 029、北京区号 010
// var reg1 = /^0731|029-\d{7,8}$/; // 错误写法
var reg2 = /^(0731|029)-\d{7,8}$/; // 正确写法
console.log(reg1.test("0731")); // true
console.log(reg2.test("0731")); // false
console.log(reg2.test("0731-1234567")); // true
- 零和非零开头的数字
^(0|[1-9][0-9]*)$
# 七、修饰符
TIP
修饰符也叫作标志(flags)通过标志,正则表达式可实现高级搜索
| 标志 | 说明 |
|---|---|
| g | 全局搜索 |
| i | 不区分大小写搜索 |
| m | 多行搜索 m 修饰符的作用是修改 ^和$在正则表达式中的作用,让它们分别表示行首和行尾。 |
| s | 允许 . 匹配换行符 |
| u | 使用 unicode 码的模式进行匹配 |
| y | 执行“粘性 (sticky)”搜索,匹配从目标字符串的当前位置开始 |
# 1、i 标志
检测字符串中是否包括大小写字母 a
var reg = /a/i;
console.log(reg.test("Abc")); // true
console.log(reg.test("abc")); // true
# 2、g 标志
- 提取字符串中的数字
var reg = /\d+/g;
var str = "1ab23c345";
var arr = str.match(reg); // 将匹配成功的内容组成一个新的数组,并将这个数组返回
console.log(arr); // ['1', '23', '345']
- 修鉓符可以组合(叠加使用)
var str = "I Love You 清心";
var res1 = str.replace(/[a-z]+/g, "*"); // 将小写字母替换成 *
console.log(res1); // I L* Y* 清心
var res2 = str.replace(/[a-z]+/gi, "*"); //将字母(不区分大小)替换成 *
console.log(res2); // * * * 清心
# 3、m 标志
TIP
- 用于将内容视为多行匹配,主要针对有
^和$修饰的表达式 - m 修饰符的作用是修改
^和$在正则表达式中的作用,让它们分别表示行首和行尾
// 提取字符串中##包裹的内容
var str = `
#a1bs##
#s@wf#
#c09swwf#
`;
var reg = /^\s*#([\s\S]+?)#\s*$/gm;
var result = [];
var res = str.replace(reg, function (v, p1) {
result.push(p1);
});
console.log(result); // ['a1bs', 's@wf', 'c09swwf']
// 以下方式更简单,但如果当前行超过两个#,就会出错
var reg = /#([\s\S]+?)#/g;
str.replace(reg, function (v, p1) {
console.log(p1);
});
- 提取第一行中数字前面紧跟随着
$或¥的数字(包括小数)
var str = `
书¥20.00
笔$30.00
本子$52
尺子¥0.5元
总费用:50.5元
`;
var reg = /(?:(?<=\$)|(?<=¥))(\d+(\.\d)?\d*).*\s/gm;
str.replace(reg, function (v, p1) {
console.log(p1);
});
# 4、s 标志
允许 . 匹配换行符
var str = `ab\n12`;
var reg = /^ab.12$/s;
console.log(reg.test(str)); // true
# 5、y 标志
TIP
- 执行
“ 粘性(sticky)”搜索,匹配从目标字符串的当前位置开始 - 使用 g 模式匹配,会一直匹配,直到整个字符串都匹配完,而使用 y 模式后,如果从 lastIndex 开始匹配不成功,则后面有符合条件的也不匹配了
- y 与 g 模式不能共存,只能二选一,同时 matchAll 不能用 y 模式
var str = "123b345ca";
var reg = /\d{2}/g;
console.log(reg.exec(str));
console.log(reg.lastIndex); // 2
console.log(reg.exec(str));
console.log(reg.lastIndex); // 6
console.log(reg.exec(str));
console.log(reg.lastIndex); // 0
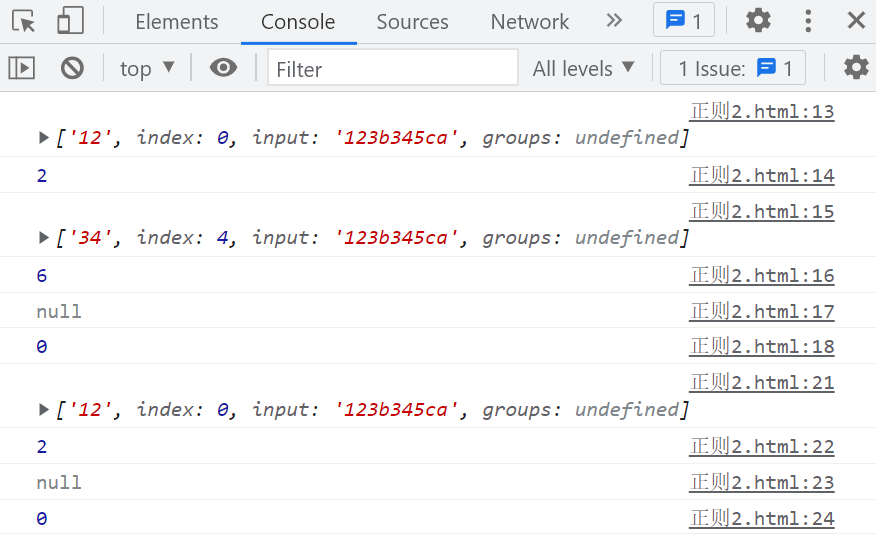
var reg = /\d{2}/y;
console.log(reg.exec(str));
console.log(reg.lastIndex); // 2
console.log(reg.exec(str)); // null
console.log(reg.lastIndex); // 0
- y 模式,主要用来提取要提取的内容是连续出现的,这样提取的效率会很高
var str =
"相关的学习QQ群:234566,90011933,30211123加入到对应群里可以获得相应的指导。以下是大神QQ群:34222222";
var reg = /(\d+),?/y;
reg.lastIndex = 9;
var res = reg.exec(str);
while (res) {
console.log(res[1]);
res = reg.exec(str);
}

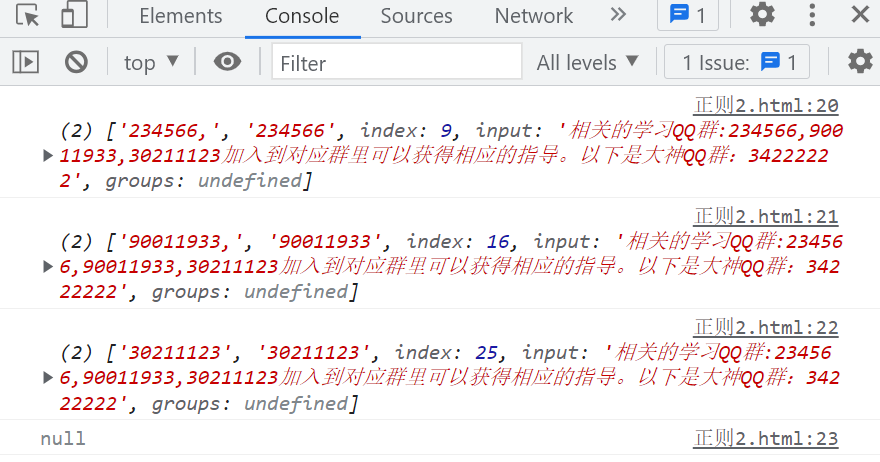
- 结合 match 使用
var str =
"相关的学习QQ群:234566,90011933,30211123加入到对应群里可以获得相应的指导。以下是大神QQ群:34222222";
var reg = /(\d+),?/y;
reg.lastIndex = 9;
var res1 = str.match(reg);
var res2 = str.match(reg);
var res3 = str.match(reg);
var res4 = str.match(reg);
console.log(res1);
console.log(res2);
console.log(res3);
console.log(res4);
var str =
"相关的学习QQ群:234566,90011933,30211123加入到对应群里可以获得相应的指导。以下是大神QQ群:34222222";
var reg = /(\d+),?/g;
var res1 = str.match(reg);
console.log(res1);

# 6、u 标志
TIP
- 使用 unicode 码的模式进行匹配
- 使用 u 模式可以正确处理 4 个字节的 UTF-16 编码
位、字节、字符:
- 位(bit):表示二进制位,位是计算机内部数据存储的最小单位,
11111111是一个 8 位的二进制 - 字节(byte):字节是计算机中数据处理的基本单位。计算机中以字节为单位存储和解释信息,规定一个字节由八个二进制位构成,即 1 个字节等于 8 个比特
(1Byte=8bit)。八位二进制数最小为00000000,最大为11111111,通常 1 个字节可以存入一个 ASCII 码,2 个字节可以存放一个汉字国标码 - 字符:字符(Character)计算机中使用的字母、数字、字和符号,比如
'A'、'B'、'$'、'&'等。 一般在英文状态下一个字母或字符占用一个字节,一个汉字用两个字节表示
Unicode 的编码
- Unicode 为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从
0x000000到0x10FFFF(十六进制),有 110 多万 - 每个字符都有一个唯一的 Unicode 编号,这个编号一般写成 16 进制,
- 例如:
“马”的 Unicode 是9A6C - 但 Unicode 本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储
var str = "马先生";
var reg = /\u9A6C/gu;
console.log(str.match(reg));
- 中文对应的 Unicode 编码表:https://www.unicode.org/charts/PDF/U4E00.pdf (opens new window)
- 全世界所有字符对应的 Unicode 编码表:http://www.unicode.org/charts/ (opens new window)
Unicode 的编码的实现方式有三种 :UTF-8、UTF-16、UTF-32
- UTF-8 编码中,一个英文和英文标点字为一个字节,一个中文和中文标点为三个字节
- UTF-16 编码中,一个英文字母字符或一个汉字字符存储都需要 2 个字节(Unicode 扩展区的一些汉字存储需要 4 个字节)
- UTF-32 编码中,世界上任何字符的存储都需要 4 个字节
UTF 后的数字代表编码的最小单位,如 UTF-8 表示最小单位 1 字节
- ASCII 码中,一个英文字母(不分大小写)为一个字节,一个中文汉字为两个字节
let str = "𝒳"; // 占两个编码单元
var reg1 = /^.$/g;
var reg2 = /^.{2}$/g;
var reg3 = /^.$/gu;
console.log(str.match(reg1)); // null
console.log(str.match(reg2)); //['𝒳']
console.log(str.match(reg3)); //['𝒳']
每个字符都有属性,但都需要结合 u 模式才有效。如
L属性表示是字母汉字,P表示标点符号,N属性表示是数字,- Lu 表示大写字母
- Ll 表示小写字母需要
- Sc 表示货币符号 ¥和 $
常见的(一般类别)General categories,它们可匹配字母、数字、符号、标点符号、空格等等。
一般类别详见地址:https://unicode.org/reports/tr18/#General_Category_Property (opens new window)
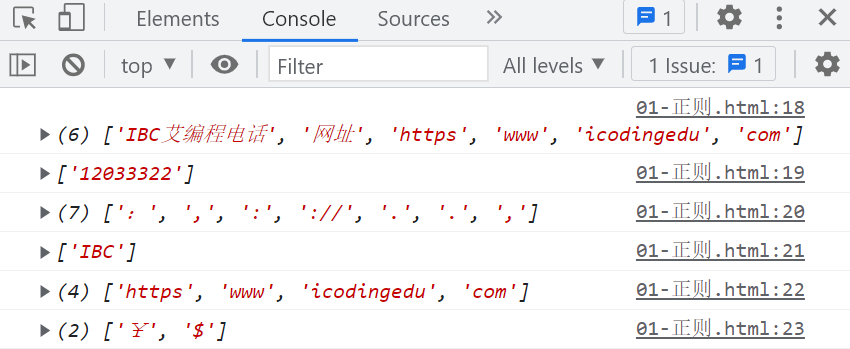
var str = "¥IBC艾编程电话:12033322,网址:https://www.icodingedu.com,$ ";
var reg1 = /\p{L}+/gu; //字母和汉字
var reg2 = /\p{N}+/gu; // 数字
var reg3 = /\p{P}+/gu; // 标点答号
var reg4 = /\p{Lu}+/gu; // 大写字母
var reg5 = /\p{Ll}+/gu; // 小写字母
var reg6 = /\p{Sc}/gu; // 匹配¥
console.log(str.match(reg1));
console.log(str.match(reg2));
console.log(str.match(reg3));
console.log(str.match(reg4));
console.log(str.match(reg5));
console.log(str.match(reg6));
- 字符也有 unicode 文字系统属性
Script = 文字系统,下面是使用\p{sc=Han}获取中文字符han为中文系统,其他语言请查看 文字语言表 (opens new window)
var str = "IBC艾编程官方网址:https://www.icodingedu.com";
var reg = /\p{sc=Han}+/gu;
console.log(str.match(reg)); // ['艾编程官方网址']
- 常用于匹配中文的正则如下
var reg = /[\u4e00-\u9fa5]+/g;
var str = "IBC艾编程官方网址:https://www.icodingedu.com";
console.log(str.match(reg)); // ['艾编程官方网址']
# 八、正则相关方法
| 方法 | 说明 |
|---|---|
test() | 测试某个字符串是否匹配正则表达式,匹配成功返回 true,否则返回 false |
exec() | 根据正则表达式,在字符串中进行查找,返回结果为 null 或数组 |
test 方法,前面我们一直在用,这里就不介绍了
# 1、exec 方法
TIP
- 在使用 exec 方法时,如果匹配失败,返回
null,同时将正则表达式的lastIndex属性值重置为0 - 如果匹配成功,则会返回一个数组,同时更新正则表达式的
lastIndex属性值。 - 如果正则中使用了
g标志,则lastIndex用来指定下一次匹配的起始索引值,否则lastIndex=0
数组中对应项
| 数组对应项 | 说明 |
|---|---|
| 第一项 | 完全匹配成功的文本 |
| 第二项 ... 第 n 项 | 每项对应一个匹配的捕获组 |
| index | 匹配成功的字符在原始字符串中的索引位置 |
| input | 匹配的原始字符串 |
| groups | 捕获组对象,其键是捕获组名,值是捕获组(值)。 如果没有定义命名捕获组,则 groups 的值为 undefined |
案例
var reg = /(\d+)([a-z])/;
var str = "ab23c345sa32";
var arr = reg.exec(str);
console.log(arr); // 返回结果见下图
console.log(reg.lastIndex); // 0 下次匹配的起始索引值

// 输出匹配成功的数组中的每一项的值
console.log(arr[0]); // 拿到匹配成功的字符
console.log(arr[1]); // 捕获组1
console.log(arr[2]); // 捕获组1
console.log(arr.index); // 匹配成功的字符串在原数组中的索引
exec 方法,默认只会输出第一次匹配成功的结果,如果后续还有匹配成功的结果,将不会输出。
# 2、exec() 方法的逐条遍历
TIP
- 当执行正则的 exec 方法时,如果正则中用
g 修饰符,则 RegExp 对象是有状态的,也就是他会将上次成功匹配后的位置记录在他的lastIndex属性中 - 利用上面这个特性,我们可以对单个字符串中的多次匹配结果进行逐条的遍历
var reg = /\d+/g;
var str = "12ab23c345";
var result1 = reg.exec(str);
console.log(reg.lastIndex); // 2
var result2 = reg.exec(str);
console.log(reg.lastIndex); // 6
var result3 = reg.exec(str);
console.log(reg.lastIndex); // 10
var result4 = reg.exec(str);
console.log(reg.lastIndex); // 0
console.log(result1, result2, result3, result4);
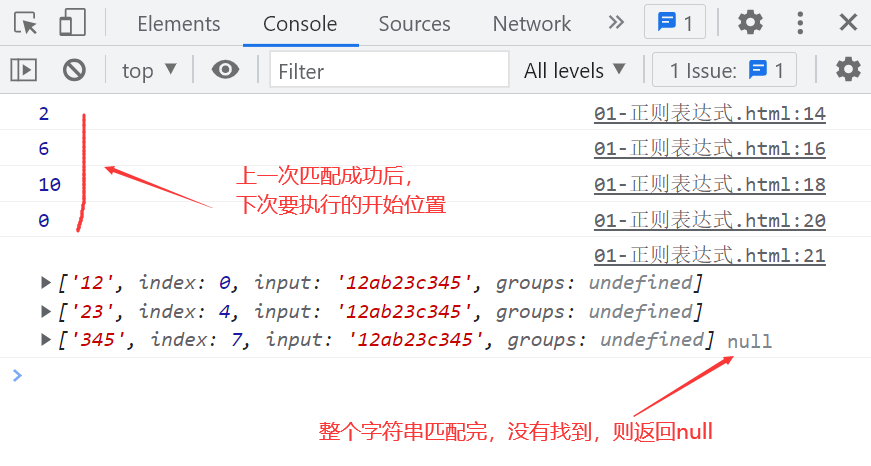
如果我们想一次性输出字符串中匹配成功的数字组成的数组,我们可以利用 while 循环来实现
/**
* search 将字符串中符合正则的字符组成数组输出
* str 要搜索的字符串
* reg 匹配的正则表达式
*/
function search(str, reg) {
var result = [];
var data = reg.exec(str);
while (data) {
result.push(data[0]);
data = reg.exec(str);
}
return result;
}
// 应用
var reg = /\d+/g;
var str = "12ab23c345";
console.log(search(str, reg)); // ['12', '23', '345']
# 3、注意事项
TIP
如果正则表达式在调用 exec 方法时,正则使用了g模式,则不要用同一个正则匹配多个字符串
如果需要,则要修正 lastIndex 的值
var reg = /(\d+)([a-z])/g;
var str1 = "ab23c345sa32";
var str2 = "12ac345sa32";
console.log(reg.exec(str1));
console.log(reg.lastIndex);
// 修正 lastIndex值
// console.log((reg.lastIndex = 0));
console.log(reg.exec(str2));
console.log(reg.lastIndex);

温馨提示
- 在实际开发中,我们很少用到 exec 方法,你可以理解为 exec 为正则表达式的原始方法
- 许多其它的正则表达式方法会在内部调用
exec(),包括一些字符串的方法
# 九、字符串相关方法
TIP
在字符串中有以下方法可以结合正则表达式来使用
| 方法 | 描述 |
|---|---|
search() | 在字符串中根据正则表达式进行查找匹配,返回首次匹配到的位置索引,测试不到则返回-1 |
match() | 在字符串中根据正则表达式进行查找匹配,返回一个数组,找不到则返回 null |
matchAll | 方法返回一个包含所有匹配正则表达式的结果及分组捕获组的迭代器。 |
replace() | 使用替换字符串替换掉匹配到的子字符串,可以使用正则表达式 |
split() | 分隔字符串为数组,可以使用正则表达式 |
# 1、search 方法
TIP
- 在字符串中根据正则表达式进行查找匹配,返回首次匹配到的位置索引,测试不到则返回
-1 - 如果传入的参数不是正则表达式,也会将其转换为正则表达式对象来处理
str.search(regexp);
- search 方法检索 love 在字符串中的位置
var str = "I love you";
var index = str.search("love"); // 2
console.log(index);
- search 方法检索字符串中 icoding 出现的位置,不分大小写
var str = "IcodingEdu";
var reg = /icoding/i;
var index = str.search(reg); // 0
console.log(index);
# 2、match 方法
TIP
- 查找字符串中与正则表达式匹配的字符,返回结果为一个数组,找不到返回
null - 如果正则使用
g标志,则返回与正则表达式匹配的所有结果,但不会返回捕获组 - 如果正则未使用
g标志,只返回第一个完整的匹配及相关的捕获组。(与 exec 方法返回结果一样)
str.match(regexp);
- 提取出字符串中所有的 a
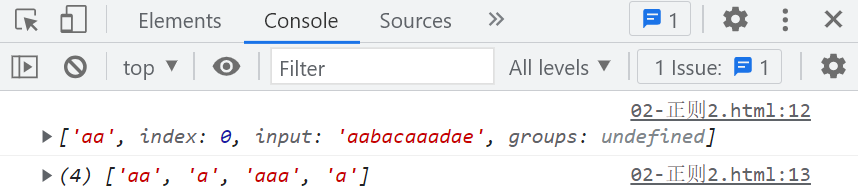
var str = "aabacaaadae";
console.log(str.match(/a+/));
console.log(str.match(/a+/g));
- 提取颜色值中的数字
var str = "rbga(23,3,44,0.1)";
var reg = /[\d]{1,3}(\.\d+)?/g;
console.log(str.match(reg)); // ['23', '3', '44', '0.1']
# 3、matchAll 方法
TIP
matchAll()方法返回一个包含所有匹配正则表达式的结果及分组捕获组的迭代器。- 正则对象必须是设置了全局模式
g的形式,否则会抛出异常TypeError - 返回值一个迭代器(不可重用,结果耗尽需要再次调用方法,获取一个新的迭代器)
matchAll 方法还存在浏览器的兼容问题
在没有 matchAll 之前,通过在循环中调用 regexp.exec() 来获取所有匹配项信息(regexp 需使用 /g 标志)
str.matchAll(regexp);
案例
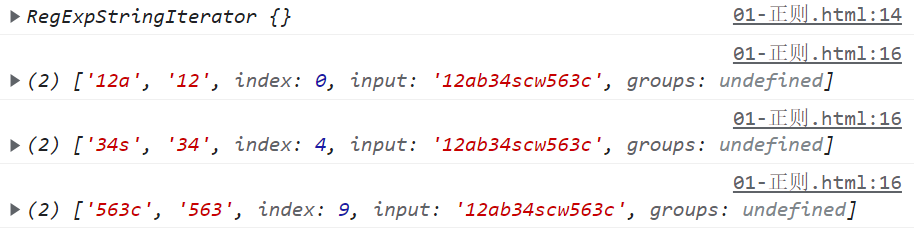
var str = "12ab34scw563c";
var reg = /(\d+)[a-z]/g;
var matches = str.matchAll(reg); // 可迭代对象
console.log(matches);
for (var item of matches) {
console.log(item);
}
// 可迭代对象不能重用,以下代码相当于没有写
for (var item of matches) {
console.log(item);
console.log("ss");
}
# 4、replace 方法
TIP
- 使用替换字符串替换掉匹配到的子字符串
- 第一个参数可以是一个正则表达式,也可以是一个字符串
- 第二个参数,可以是一个字符串,也可以是一个函数,这个函数用来创建新子字符串,该函数的返回值将替换掉第一个参数匹配到的结果
str.replace(regexp|substr, newSubStr|function)
- 将字符串中的字母全部过滤掉,只留下数字
var str = "abc123fe4swfe56sw342";
var result = str.replace(/[a-zA-Z]+/g, "*");
console.log(result); // *123*4*56*342
- 脏字过滤,将字符串中的所有垃圾,替换成*号
var str = "垃圾还是垃圾,把垃圾";
var result1 = str.replace("垃圾", "*"); // 只能替换第一个垃圾为*
console.log(result1); // *还是垃圾,把垃圾
var reg = /垃圾/g;
var result2 = str.replace(reg, "*"); // 将字符串中所有垃圾替换为 *
console.log(result2); // *还是*,把*
replace 方法与原子组相关的结合,还有第二个参数为函数的情况,后面讲原子组是再细讲解
# 5、split 方法
TIP
- 使用正则表达式或一个固定的字符串来分隔一个字符串,并将分隔后的子字符串存储到数组中
- 返回结果为分隔后的字符串形成的数组
str.split([separator[, limit]])
// separator 分隔符
// limit 整数,限定返回的分割片段数量
- 用数字来分隔字符串
var str = "ab12de34swfe4fe6";
var result = str.split(/\d+/);
console.log(result); // ['ab', 'de', 'swfe', 'fe', '']
- 用
/或-来分隔日期
var str1 = "2022/09/08";
var str2 = "2022-07-08";
var reg = /[-/]/;
console.log(str1.split(reg)); // ['2022', '09', '08']
console.log(str2.split(reg)); // ['2022', '07', '08']
// 分隔后,我只想要年份和月份
console.log(str2.split(reg, 2)); // ['2022', '07']
# 十、原子组
TIP
- 在正则中我们可以利用
()对匹配项进行分组,并能记住该匹配项等。 ()中的内容,我们也称为子表达式- 捕获:在正则表达式中,子表达式匹配到相应的内容时,系统会自动捕获这个行为,然后将子表达式匹配到的内容放入系统的缓存区中。我们把这个过程称之为**“捕获”**
| 字符集 | 说明 |
|---|---|
(x) | 捕获组 匹配'x' 并且记住匹配项。其中括号被称为捕获括号。正则中的 \1、\2、... \n 分别表示第一个、第二个、... 第n个被捕获括号匹配的子字符串(也称反向引用)在正则表达式的替换环节,即 str.replace(/(..)(...)/,'$2 $1) 中,$1和$2分别表示第一个和第二被捕获括号匹配的子字符串在正则表达式替换环节, $& 表示整个用于匹配的原字符串 |
(?:x) | 非捕获组 匹配'x'但是不记住匹配项。这种括号叫作非捕获括号,使得你能够定义与正则表达式运算符一起使用的子表达式 |
(?<name>x) | 具名捕获组 匹配 "x"并将其存储在返回的匹配项的 groups 属性中,该属性位于<name>指定的名称下 |
| $反引号 | $反引号 匹配成功的内容的左边 |
$’ | $单引号 匹配成功的内容的右边 |
# 1、(x) 捕获括号
TIP
(x)用来表示捕获组,匹配'x'并且记住匹配项- 正则中的
\1、\2、... \n分别表示第一个、第二个、... 第n个被捕获括号匹配的子字符串
案例: 匹配日期格式是否是以-或/相连,如:2022-09-09 或 2022/09/08
var dateString1 = "2022-2/08";
var dateString2 = "2022-2-08";
var reg = /^\d{4}([-/])\d{1,2}\1\d{1,2}$/;
console.log(reg.test(dateString1)); // false
console.log(reg.test(dateString2)); // true
- 在正则表达式的替换环节,即
str.replace(/(..)(...)/,'$2 $1)中,$1和$2分别表示第一个和第二被捕获括号匹配的子字符 串
案例: 将日期2022-09-08 倒过来展示08-09-2022
var dateString2 = "2022-09-08";
var reg = /^(\d{4})([-/])(\d{1,2})\2(\d{1,2})$/;
var res = dateString2.replace(reg, "$4$2$3$2$1");
console.log(res); // 08-09-2022
案例: 将(010)12398765 更改变010-12398765
var datestring = "(010)12398765";
var reg = /^\((\d{3,4})\)(\d{7,8})$/g;
var res = datestring.replace(reg, "$1-$2");
console.log(res);
- 在正则表达式替换环节,
$&表示整个用于匹配的原字符串
案例: 将字符串中的艾编程添加链接
<div class="info">
艾编程是在大数据人工智能时代高速发展的今天成立的一家以提供各行业商业项目研发解决方案为核心的在线教育学习平台。
</div>
<script>
var info = document.querySelector(".info");
var inner = info.innerHTML;
var reg = /艾编程/;
info.innerHTML = inner.replace(
reg,
"<a href='http://www.icodingedu.com'>$&</a>"
);
</script>
注意事项: 在数捕获括号时,从左往右数
(括号个数
var str = "12abs#B@12abs12#B@#B@";
var reg = /^((\d+)[a-z]+)((#)([A-Z]@))\1\2\3\4\5$/;
console.log(reg.test(str));
// \1 ((\d+)[a-z]+)
// \2 (\d+)
// \3 ((#)([A-Z]@)) #B@
// \4 (#)
// \5 ([A-Z]@)
在正则表达式替换环节,replace 方法的第二个参数如果是一个函数,则函数中参数详情如下:
str.replace(regexp,function(v,p1,p2,index,input,groups))
- 第一个参数
v是匹配成功的那个字符串 - 参数
p1,p2, ...依次为第一个和第二被捕获括号匹配的子字符串 - index 为当前匹配成功项的开始索引
- input 为原始匹配的字符串
- groups 捕获组对象(具名捕获组组成的一个对象)
案例
var str = "12aw332sewe244sw";
var reg = /(?<number>\d+)/g;
str.replace(reg, function (v, p1, index, s, groups) {
console.log(v, p1, index, s, groups);
});

var str = "12a.b34cd45";
var reg = /((\d{2})([a-c]))(\.)\w+/g;
str.replace(reg, function (v, p1, p2, p3, p4) {
console.log(v); // 12a.b34cd45
console.log(p1); // 12a
console.log(p2); // 12
console.log(p3); // a
console.log(p4); // .
});
# 2、(?:x)非捕获组
TIP
- 非捕获组 匹配
'x'但是不记住匹配项。这种括号叫作非捕获括号 - 使得你能够定义与正则表达式运算符一起使用的子表达式
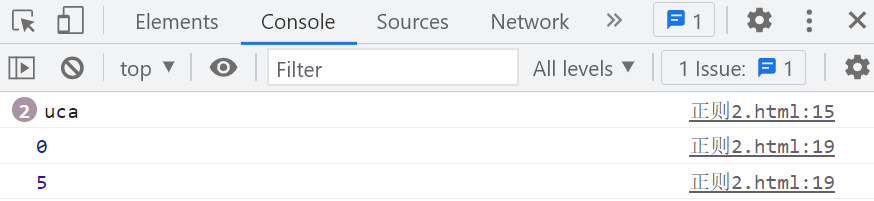
var str1 = "ucaaauca";
var reg1 = /uca+/g; // 表示a出现1次或多次
var reg2 = /(uca)+/g; // 表示uca整体出现1次或多次
console.log(str1.match(reg1));
console.log(str1.match(reg2));
- 如果不想记住
()中的匹配项,则可以用?:
var str1 = "ucaaauca";
var reg1 = /(uca)+/g; // 表示uca整体出现1次或多次
var reg2 = /(?:uca)+/g; // 表示uca整体出现1次或多次
str1.replace(reg1, function (v, p1) {
console.log(p1);
});
str1.replace(reg2, function (v, p1) {
console.log(p1); //并没有捕获组内容,打印内容为捕获成功字符串的起始索引
});
# 3、(?<name>x) 具名捕获组
TIP
匹配 "x" 并将其存储在返回的匹配项的 groups 属性中,该属性位于<name>指定的名称下
var str = "abc123def576";
var reg = /[a-z]+(?<number>\d+)/g;
var number = []; // 用来存放结果数据
var arr = reg.exec(str);
while (arr) {
number.push(arr.groups.number); // 匹配的每一项的数字存到数组中
arr = reg.exec(str);
}
console.log(number);
- 在正则表达式中,引用具名捕获组,可以使用
\k<name>的写法,当然之前的\n(n 是一个整数)的写法也是可行的
var str = "a111222";
var reg = /[a-z](?<number>1)\k<number>\1/g;
console.log(str.match(reg)); // a111
- 在 replace 方法中,使用
$<name>引用具名组
var str = "a111222";
var reg = /[a-z](?<number>1)\k<number>\1/g;
console.log(str.replace(reg, "*$<number>*")); // *1*222
# 4、$` 表示匹配成功的内容的左边
var str = "abcA123";
var reg = /\A/;
var res = str.replace(reg, "$`");
console.log(res); // abcabc123
# 5、$' 表示匹配成功的内容的右边
var str = "abcA123";
var reg = /\A/;
var res = str.replace(reg, "$'");
console.log(res); // abc123123
# 十一、?禁止贪婪
TIP
?如果紧跟在任何量词\*、 +、? 或{} 的后面,将会使量词变为非贪婪(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反
var str = "abcddddcdddd";
var reg = /cd+?/g;
var res = str.match(reg);
console.log(res); // ['cd', 'cd']
var str = "abdacd";
var reg1 = /\w+d/g;
var reg2 = /\w+?d/g;
console.log(str.match(reg1));
console.log(str.match(reg2));

- 匹配出 span 标签中的内容
<div class="box">
<span>清心</span>
<span>艾编程</span>
<span>前端</span>
</div>
<script>
var box = document.querySelector(".box");
var inner = box.innerHTML;
var reg = /<span>([\s\S]+?)<\/span>/g;
var result = [];
inner.replace(reg, function (v, p1) {
result.push(p1);
});
console.log(result); // ['清心', '艾编程', '前端']
</script>
- 匹配对应的标签
<div class="box">
我秒是我
<p>艾编程</p>
<h3>清心老师</h3>
<div>前端内容</div>
<p></p>
</div>
<script>
var box = document.querySelector(".box");
var innerHTML = box.innerHTML;
var reg = /<([a-z]+\d?)>[\s\S]*?<\/\1>/gi;
var res = innerHTML.match(reg);
console.log(res);
</script>
# 十二、断言匹配
| 字符 | 说明 |
|---|---|
x(?=y) | 先行断言:x的右边被y紧跟随之时匹配x |
(?<=y)x | 后行断言:x 的左边紧跟随y时,匹配x |
x(?!y) | 先行否定断言: x右边没有被y紧跟随之时匹配x |
(?<!y)x | 后行否定断言: x的左边没有被y紧随时匹配x |
# 1、x(?=y)
TIP
先行断言(正向预查、正预测、前瞻):
x的右边被y紧跟随之时匹配xy不是匹配结果的一部分先行断言是从左往右看
# 1.1、提取 x 字符后面紧跟随 xxx 字符的 x 字符
- 将字符串中
a后面紧跟随c的a替换成*号
var str = "abcacaecac";
var reg = /a(?=c)/g;
str = str.replace(reg, "*");
console.log(str); // abc*caec*c
- 将字符串中 web 前端或 java 后面紧跟随视频的 web 前端和 java 变成红色 (字母不区分大小写)
<div class="box"></div>
<script>
var box = document.querySelector(".box");
var str =
"艾编程教育提供相关Web前端、java教程,相关视频地址:web前端视频,Java视频等";
var reg = /(?:web前端|java)(?=视频)/gi;
box.innerHTML = str.replace(reg, function (v) {
return "<span style='color:red'>" + v + "</span>";
});
</script>
# 1.2、理解 x(?=y)(?=z) 匹配
x(?=y)(?=z)表示 x 的后面(右边)要紧跟随着 y,同时又要紧跟随着 z
var reg = /1(?=a)(?=A)/g; // 表示1后面必需紧跟着a,同时又要紧跟着A,这种情况肯定是不成立的
var str = "1aA";
console.log(str.match(reg)); // null
// 添加i标志,也就是对a和A不区分大小写时,也就成立
var reg = /1(?=a)(?=A)/gi;
var str = "1a";
console.log(str.match(reg)); // ['1']
var reg = /(?=1)(?=\d)(?=\w)/g;
console.log("1".match(reg)); // ['']
console.log("a1".match(reg)); // ['']
console.log("2".match(reg)); //null
- 匹配 a 后面紧跟 1 或紧跟随 2 的 a,替换成
*号
var reg = /a((?=1)|(?=2))/g;
console.log("a1ab".replace(reg, "*")); // *1ab
console.log("a2ac".replace(reg, "*")); // *2ac
console.log("a3ad".replace(reg, "*")); // a3ad
# 1.3、理解 /(?=.*y)(?=.*z)/ 匹配
/(?=.*y)(?=.*z)/ 表示字符串中必需出现 y 和 z 字符
- 某个字符串中必需出现 艾编程
var reg = /艾编程/;
console.log(reg.test("艾编程教育"));
console.log(reg.test("西安艾编程"));
console.log(reg.test("艾编程"));
- 匹配的字符串中必需包含:艾编程、前端 这两组词
var reg = /(?=.*艾编程)(?=.*前端)/;
console.log(reg.test("艾编程有前端课程"));
console.log(reg.test("前端方面的课程艾编程有"));
console.log(reg.test("艾编程前端"));
console.log(reg.test("艾编程有web端"));
- 字符串的长度为 8 位,但必需包含:艾编程、前端 这两组词
// 某个字符串中必需包含 艾编程、前端
var reg = /^(?=.*艾编程)(?=.*前端).{8}$/g;
console.log(reg.test("艾编程有前端课程")); // true
console.log(reg.test("艾编程有web前端")); // false
console.log(reg.test("艾编程前端")); // true
var str1 = "艾编程有前端课程";
var str2 = "艾编程有web前端";
var str3 = "艾编程前端";
console.log(str1.match(reg)); //['艾编程有前端课程']
console.log(str2.match(reg)); // null
console.log(str3.match(reg)); // null
- 匹配的字符串长度为
6-8位的,但必须包含至少一个大写字母、一个小写字母和一个数字,同时不能有空白字符
var reg = /^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)\S{6,8}$/;
console.log(reg.test("A123q222")); // true
console.log(reg.test("2Wswee222")); // false
console.log(reg.test("sww1A")); // false
console.log(reg.test("sww1A2")); // true
# 2、(?<=y)x
TIP
- 后行断言:
x的左边紧跟随y时,匹配x - y 不是匹配结果的一部分
- 后行断言是从右往左看(先看右边,再看左边)
# 2.1、提取 x 前面(左边)紧跟随 xxx 字符的 x
- 获取数字前面(左边)紧跟随字母的数字
var str = "a12bc43bc32";
var reg = /(?<=\w)\d+/g;
console.log(str.match(reg)); // ['12', '43', '32']
- 将 11 位电话号码的后 4 位替换成
****号
// 将电话号码的后四位改变****
var tel = "清心电话:12323457612";
var reg = /(?<=\d{7})\d{4}/g;
var res = tel.replace(reg, "****");
console.log(res); // 清心电话:1232345****
- 将视频的前面是前端的 ”视频“ 替换成 ”视频教程“
var reg = /(?<=前端)视频/g;
var str = "艾编程前端视频,java视频";
console.log(str.match(reg));
var res = str.replace(reg, function (v) {
return v + "教程";
});
console.log(res);
# 2.2、理解(?<=y)(?<=z)x 匹配
(?<=y)(?<=z)x 表示前面要紧跟着 y 同时又要紧跟随着 z
var str = "a1";
var reg = /(?<=A)(?<=a)1/g; // 表示 1前面要紧跟随着A同时又要紧跟随着a,显然是不可能成立的
console.log(str.match(reg)); // null
var str = "a1";
var reg = /(?<=A)(?<=a)1/gi; // 添加了i标志,这样A和a不区分大小写,相当于是一样的
console.log(str.match(reg)); // ['1']
- 获取字符串中数字(包括小数)前被
¥或$跟随的数字
var str = `
书¥20.00
笔$30.00
本子$52
尺子¥0.5
总费用:50.5元
`;
var reg = /((?<=\$)|(?<=¥))(\d+(\.\d)?\d*)/g;
console.log(str.match(reg));
# 2.3、区分 /(?<=.*y)(?<=.*z)x/ 与 /(?<=y.*)(?<=z.*)x/
/(?<=.*y)(?<=.*z)/表示 x 前面紧跟随着 y 同时又要紧跟随着 x/(?<=y.*)(?<=z.*)x/表示 x 前面必需包含 y,同时又包含 z
var reg = /(?<=.*a)(?<=.*b)/g;
var str = "ab";
console.log(str.match(reg)); // null
var reg = /(?<=.*\d)(?<=.*1)/g;
var str = "a1";
console.log(str.match(reg)); // ['']
- 字符串中必需包含 a 和 b
var reg = /(?<=a.*)(?<=b.*)/g;
console.log("ab".match(reg)); // ['']
console.log("1ab".match(reg)); // ['']
console.log("ab1".match(reg)); // ['', '']
console.log(reg.test("ab")); // true
console.log(reg.test("1ab")); // true
console.log(reg.test("ab1")); // true
- 检测字符串是否为
6-8位,同时必需包含大写 A 和小写 a 和数字
var reg = /^.{6,8}(?<=[A-Z].*)(?<=[a-z].*)(?<=[0-9].*)$/g;
console.log("aAwwi9$@".match(reg));
console.log("aAwwi9$@3".match(reg));
console.log("aAww*&".match(reg));
console.log("aAww*1".match(reg));
# 3、x(?!y)
TIP
先行否定断言(也称正向否定查找):x 右边没有被y紧跟随之时匹配x
var str = "ab123abc";
var reg = /[a-z]+(?!\d)/g;
console.log(str.match(reg)); // ['a', 'abc']
# 4、(?<!y)x
- 后行否定断言(也称反向否定查找):
x的左边没有被y紧随时匹配x
var str = "ab123abc";
var reg = /(?<!\d)[a-z]+/g;
console.log(str.match(reg)); // ['ab', 'bc']
- 中国邮政编码 (中国邮政编码为 6 位数字,第一位不能是 0)
var str = "A区邮政编码:1234567 B区邮政编码:129832";
var reg = /(?<!\d)[1-9]\d{5}(?!\d)/g;
console.log(str.match(reg));
# 十三、正则表达式应用案例
TIP
将所学知识在实际项目场景中应用和实践
# 1、批量使用正则完成某个验证
TIP
用户名只能是数字和字母组成,但必需包含一个大写字母
var str = "abc123_s";
const regs = [/^[a-z0-9_]{5,10}$/i, /[A-Z]/];
// state=true表示字符串能通过所有正则的检测 ,假设一开始为true
var state = true;
for (var i = 0; i < regs.length; i++) {
state = regs[i].test(str);
// 只要有一次检测为false,则表示字符串没有通过检测
if (!state) {
break;
}
}
// 根据state的值来判断字符串是否符合要求
if (!state) {
console.log("字符串不满足要求");
} else {
console.log("字符串满足要求");
}
利用数组的 every 方法来实现
var str = "abc1234_s";
const regs = [/^[a-z0-9_]{5,10}$/i, /[A-Z]/];
var state = regs.every(function (item) {
return item.test(str);
});
console.log(state);
# 2、用户注册密码验证,项目实践

<style>
html,
body,
p {
margin: 0;
padding: 0;
}
.register {
width: 300px;
margin: 100px;
}
.tip {
border: 1px solid skyblue;
background-color: rgb(227, 245, 252);
border-radius: 10px;
padding-left: 10px;
margin-top: 30px;
}
.tip p {
line-height: 35px;
padding-left: 28px;
background: url("./images/cha.png") no-repeat left center;
background-size: 20px 20px;
color: #666;
}
.tip p.gou {
background-image: url("./images/gou.png");
background-size: 32px 32px;
color: rgb(16, 184, 250);
}
.pwd input {
height: 45px;
width: 100%;
box-sizing: border-box;
border-radius: 5px;
outline: none;
border: 1px solid #666;
}
.pwd input::placeholder {
font-size: 20px;
position: relative;
top: 2px;
left: 10px;
}
</style>
<div class="register">
<div class="pwd">
<input type="text" placeholder="密码" class="password" />
</div>
<div class="tip">
<p class="upper">至少有一个大写字母</p>
<p class="lower">至少有一个小写字母</p>
<p class="number">至少有一个数字</p>
<p class="special">至少有一个特殊字符</p>
<p class="blank-space">不能以空白符开头</p>
<p class="length">密码长度8-12之间</p>
</div>
</div>
<script>
var input = document.querySelector(".password");
var upperEl = document.querySelector(".upper");
var lowerEl = document.querySelector(".lower");
var numberEl = document.querySelector(".number");
var specialEl = document.querySelector(".special");
var blankSpaceEl = document.querySelector(".blank-space");
var lengthEl = document.querySelector(".length");
input.onkeyup = function () {
var value = this.value; // 输入框内容
// 正则判断
var upper = /(?=.*[A-Z])/;
var lower = /(?=.*[a-z])/;
var number = /(?=.*[0-9])/;
var special = /(?=.*[!@#$%^&*?])/;
var blankSpace = /^\S/;
var length = /^.{8,12}$/;
// 至少一个大写字母
if (upper.test(value)) {
upperEl.classList.add("gou");
} else {
upperEl.classList.remove("gou");
}
// 至少一个小写字母
if (lower.test(value)) {
lowerEl.classList.add("gou");
} else {
lowerEl.classList.remove("gou");
}
// 至少一个数字
if (number.test(value)) {
numberEl.classList.add("gou");
} else {
numberEl.classList.remove("gou");
}
// 至少一个数字
if (special.test(value)) {
specialEl.classList.add("gou");
} else {
specialEl.classList.remove("gou");
}
// 没有以空白字符开头
if (blankSpace.test(value)) {
blankSpaceEl.classList.add("gou");
} else {
blankSpaceEl.classList.remove("gou");
}
// 密码长度在8-12之间
if (length.test(value)) {
lengthEl.classList.add("gou");
} else {
lengthEl.classList.remove("gou");
}
};
</script>
# 十四、正则相关工具
TIP
- 正则在线测试工具:https://regexr-cn.com (opens new window)
- VsCode 插件:any-rule 提供了常用的正则表达式,直接拿来即用
# 1、校验数字的表达式
TIP
- 1、数字:
^[0-9]*$ - 2、n 位的数字:
^\d{n}$ - 3、至少 n 位的数字:
^\d{n,}$ - 4、
m-n位的数字:^\d{m,n}$ - 5、零和非零开头的数字:
^(0|[1-9][0-9]*)$ - 6、非零开头的最多带两位小数的数字:
^([1-9][0-9]*)+(\.[0-9]{1,2})?$ - 7、带
1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$ - 8、正数、负数、和小数:
^(\-|\+)?\d+(\.\d+)?$ - 9、有两位小数的正实数:
^[0-9]+(\.[0-9]{2})?$ - 10、有
1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$ - 11、非零的正整数:
^[1-9]\d*$或^([1-9][0-9]*){1,3}$或^\+?[1-9][0-9]*$ - 12、非零的负整数:
^\-[1-9][]0-9"*$或^-[1-9]\d*$ - 13、非负整数:
^\d+$或^[1-9]\d*|0$ - 14、非正整数:
^-[1-9]\d*|0$或^((-\d+)|(0+))$ - 15、非负浮点数:
^\d+(\.\d+)?$或^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ - 16、非正浮点数:
^((-\d+(\.\d+)?)|(0+(\.0+)?))$或^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ - 17、正浮点数:
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$或^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$ - 18、负浮点数:
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$或^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$ - 19、浮点数:
^(-?\d+)(\.\d+)?$或^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
# 2、校验字符的表达式
TIP
- 1、汉字:
^[\u4e00-\u9fa5]{0,}$ - 2、英文和数字:
^[A-Za-z0-9]+$或^[A-Za-z0-9]{4,40}$ - 3、长度为 3-20 的所有字符:
^.{3,20}$ - 4、由 26 个英文字母组成的字符串:
^[A-Za-z]+$ - 5、由 26 个大写英文字母组成的字符串:
^[A-Z]+$ - 6、由 26 个小写英文字母组成的字符串:
^[a-z]+$ - 7、由数字和 26 个英文字母组成的字符串:
^[A-Za-z0-9]+$ - 8、由数字、26 个英文字母或者下划线组成的字符串:
^\w+$ 或^\w{3,20}$ - 9、中文、英文、数字包括下划线:
^[\u4E00-\u9FA5A-Za-z0-9_]+$ - 10、中文、英文、数字但不包括下划线等符号:
^[\u4E00-\u9FA5A-Za-z0-9]+$或^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$ - 11、可以输入含有
^%&',;=?$\"等字符:[\^%&',;=?$\\]+ - 12、禁止输入含有
~的字符:[^~]+
# 3、特殊需求表达式
TIP
- 1、Email 地址:
^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ - 2、域名:
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.? - 3、InternetURL:
[a-zA-z]+://[^\s]*或^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$ - 4、手机号码:
^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$ - 5、电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):
^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$ - 6、国内电话号码(0511-4405222、021-87888822):
\d{3}-\d{8}|\d{4}-\d{7} - 7、电话号码正则表达式(支持手机号码,3-4 位区号,7-8 位直播号码,1-4 位分机号):
((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$) - 8、身份证号(15 位、18 位数字),最后一位是校验位,可能为数字或字符 X:
(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$) - 9、帐号是否合法(字母开头,允许 5-16 字节,允许字母数字下划线):
^[a-zA-Z][a-zA-Z0-9_]{4,15}$ - 10、密码(以字母开头,长度在 6~18 之间,只能包含字母、数字和下划线):
^[a-zA-Z]\w{5,17}$ - 11、强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$ - 12、强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在 8-10 之间):
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ - 13、日期格式:
^\d{4}-\d{1,2}-\d{1,2} - 14、一年的 12 个月(01 ~ 09 和 1 ~ 12):
^(0?[1-9]|1[0-2])$ - 15、一个月的 31 天(01 ~ 09 和 1 ~ 31):
^((0?[1-9])|((1|2)[0-9])|30|31)$ - 16、钱的输入格式: 有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000" :
^[1-9][0-9]*$ - 17、这表示任意一个不以 0 开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:
^(0|[1-9][0-9]*)$ - 18、一个 0 或者一个不以 0 开头的数字,我们还可以允许开头有一个负号:
^(0|-?[1-9][0-9]*)$ - 19、这表示一个 0 或者一个可能为负的开头不为 0 的数字,让用户以 0 开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:
^[0-9]+(.[0-9]+)?$ - 20、必须说明的是,小数点后面至少应该有 1 位数,所以
"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$ - 21、这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:
^[0-9]+(.[0-9]{1,2})?$ - 22、这样就允许用户只写一位小数,下面我们该考虑数字中的逗号了,我们可以这样:
^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$ - 23、1 到 3 个数字,后面跟着任意个 逗号+3 个数字,逗号成为可选,而不是必须:
^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$ - 24、备注:这就是最终结果了,别忘了
"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里 - 25、xml 文件:
^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$ - 26、中文字符的正则表达式:
[\u4e00-\u9fa5] - 27、双字节字符:
[^\x00-\xff](包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计 2,ASCII 字符计 1 )) - 28、空白行的正则表达式:
\n\s*\r(可以用来删除空白行) - 29、HTML 标记的正则表达式:
<(\S*?)[^>]*>.*?|<.*? />(首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$)(可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式) - 30、腾讯 QQ 号:
[1-9][0-9]{4,}(腾讯 QQ 号从 10000 开始) - 31、中国邮政编码:
[1-9]\d{5}(?!\d)(中国邮政编码为 6 位数字) - 32、IPv4 地址:
((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
# 十五、重难点总结
TIP
总结本章重难点知识,理清思路,把握重难点。并能轻松回答以下问题,说明自己就真正的掌握了。
用于故而知新,快速复习。
# 1、重点
TIP
- 正则表达式的两种创建形式
- 掌握边界限定符
^ $ \b \B的用法 - 掌握 量词、[] 方括号、选择符| 的用法
- 掌握常见的标志(修饰符) i、g、m、s 的应用
- 掌握正则的 test、exec 方法
- 掌握字符串的 search、match、matchAll、replace、split 方法
- 掌握 vscode 插件
any-rule的用法
# 2、难点
TIP
- 掌握原子组(子表达式)以下用法
(x)捕获组(?:x)非捕获组(?<name>x)具名捕获组
- 掌握
?禁止贪婪的用法 - 掌握断言匹配
- 手写正则表达式满足以下条件:字符串为 8-12 位(除空白字符的任意字符),同时必需要有一个大写字母,一个小写字母,一个数字,一个特殊字符组成
- 手写课上讲到的注册密码验证案例
大厂最新技术学习分享群

微信扫一扫进群,获取资料
X